
With Predictive modeling techniques at the forefront, this paragraph opens a window to an amazing start and intrigue, inviting readers to embark on a storytelling semrush author style filled with unexpected twists and insights.
Unveiling the power of predictive modeling techniques in deciphering complex data patterns, this topic delves into a realm where data-driven decisions shape the future of industries across the globe.
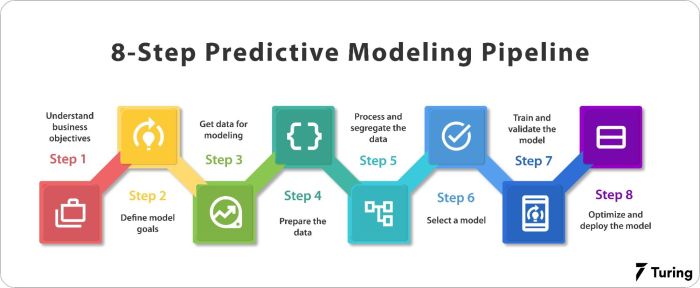
Overview of Predictive Modeling Techniques

Predictive modeling techniques involve using statistical algorithms and machine learning to analyze historical data and make predictions about future outcomes. This process helps businesses and organizations make informed decisions based on data-driven insights.
Predictive modeling is essential in various industries such as finance, healthcare, retail, marketing, and more. It enables companies to forecast trends, optimize operations, mitigate risks, and improve overall decision-making processes. By leveraging predictive modeling, organizations can identify patterns, make accurate predictions, and gain a competitive edge in the market.
Real-World Applications of Predictive Modeling Techniques
- Predictive maintenance in manufacturing industries to anticipate equipment failures and minimize downtime.
- Healthcare providers use predictive modeling to identify patients at risk of certain diseases and personalize treatment plans.
- Financial institutions utilize predictive modeling for credit scoring, fraud detection, and investment forecasting.
- Retail companies apply predictive modeling to optimize pricing strategies, forecast demand, and enhance customer segmentation.
Types of Predictive Modeling Techniques

Predictive modeling techniques encompass a variety of methods used to predict outcomes based on historical data. Each type of technique has its own strengths and weaknesses, making them suitable for different scenarios. Let’s explore some common types of predictive modeling techniques and their characteristics.
Regression Analysis
Regression analysis is a statistical method that examines the relationship between a dependent variable and one or more independent variables. It is widely used for predicting continuous outcomes. One of the main advantages of regression analysis is its simplicity and interpretability, making it easy to understand the impact of each predictor on the outcome. However, it assumes a linear relationship between variables, which may not always hold true in real-world data. Regression analysis is most effective when predicting outcomes with a linear relationship, such as predicting sales based on advertising spend.
Decision Trees
Decision trees are a popular predictive modeling technique that uses a tree-like structure to represent decisions and their possible consequences. They are easy to interpret and can handle both categorical and continuous data. Decision trees are advantageous for capturing interactions between variables and identifying important predictors. However, they are prone to overfitting, especially with complex data. Decision trees are most effective in scenarios where the decision-making process can be represented in a hierarchical, tree-like structure, such as classifying customer behavior based on demographic information.
Neural Networks
Neural networks are a type of machine learning algorithm inspired by the human brain’s neural networks. They are capable of learning complex patterns and relationships in data, making them suitable for predicting nonlinear outcomes. Neural networks excel at handling large amounts of data and can adapt to different types of problems. However, they are often considered black-box models, making it difficult to interpret their decisions. Neural networks are most effective in scenarios where the relationship between predictors and outcomes is nonlinear, such as image recognition or natural language processing tasks.
Data Preparation for Predictive Modeling

Data preparation is a crucial step in predictive modeling as it directly impacts the accuracy and performance of the model. It involves cleaning and transforming raw data into a format that is suitable for analysis and modeling.
Significance of Data Preprocessing
Data preprocessing plays a vital role in predictive modeling by ensuring that the dataset is clean, consistent, and relevant for building accurate models. It involves handling missing values, dealing with outliers, and transforming features to improve model performance.
- Cleaning the Data: Removing irrelevant or duplicate data, correcting errors, and standardizing formats to ensure data quality.
- Feature Engineering: Creating new features, transforming existing features, and selecting relevant features to improve the predictive power of the model.
- Handling Missing Data: Imputing missing values using techniques like mean, median, mode imputation, or advanced methods like predictive modeling.
- Dealing with Outliers: Identifying and treating outliers to prevent them from skewing the model’s predictions or affecting its performance.
Common Techniques for Data Cleaning and Feature Engineering
- Data Cleaning Techniques:
- Removing duplicates, irrelevant, or inconsistent data.
- Standardizing data formats and correcting errors.
- Handling missing values through imputation or deletion.
- Feature Engineering Techniques:
- Creating new features based on existing ones.
- Transforming features to improve their predictive power.
- Selecting relevant features using techniques like feature importance ranking or dimensionality reduction.
Handling Missing Data and Outliers
- Missing Data:
- Identify missing values in the dataset.
- Impute missing values using methods like mean, median, mode imputation, or predictive modeling.
- Avoid removing rows with missing values unless absolutely necessary to preserve data integrity.
- Outliers:
- Identify outliers using statistical methods like Z-score, IQR, or visualization techniques.
- Treat outliers by capping/extending values, transforming data, or removing outliers based on domain knowledge.
- Be cautious when handling outliers as they can significantly impact the model’s performance.
Model Evaluation and Selection
Model evaluation and selection are crucial steps in predictive modeling to ensure the best performing model is chosen for deployment. This involves assessing the model’s performance using key metrics, selecting the most suitable model based on evaluation results, and implementing techniques to prevent overfitting and underfitting.
Key Metrics for Model Evaluation, Predictive modeling techniques
When evaluating predictive models, several key metrics are commonly used to assess their performance. These metrics include:
- Accuracy: Measures the proportion of correctly classified instances out of the total number of instances in the dataset.
- Precision: Indicates the proportion of true positive predictions out of all positive predictions made by the model.
- Recall: Also known as sensitivity, measures the proportion of true positive predictions out of all actual positive instances in the dataset.
- F1 Score: Combines precision and recall into a single metric, providing a balanced measure of a model’s performance.
- ROC-AUC: Represents the area under the receiver operating characteristic curve, which evaluates the trade-off between true positive rate and false positive rate.
Selecting the Best Model
After evaluating models using the key metrics mentioned above, the next step is to select the best model for deployment. This process involves comparing the performance of different models and choosing the one that demonstrates the highest accuracy, precision, recall, or F1 score, depending on the specific requirements of the project.
Preventing Overfitting and Underfitting
Overfitting and underfitting are common challenges in predictive modeling that can adversely affect a model’s performance. To prevent these issues, techniques such as:
- Cross-validation: Dividing the dataset into multiple subsets for training and testing to ensure the model generalizes well to unseen data.
- Regularization: Adding a penalty term to the model’s loss function to prevent overfitting by discouraging overly complex models.
- Feature selection: Selecting only the most relevant features to avoid overfitting caused by irrelevant or redundant variables.
- Early stopping: Stopping the training process before the model starts overfitting the training data by monitoring performance on a separate validation set.
can be employed to improve the model’s generalization capabilities and overall performance.
Advanced Concepts in Predictive Modeling: Predictive Modeling Techniques
Predictive modeling techniques can be taken to the next level by incorporating advanced concepts such as ensemble methods, cross-validation, and hyperparameter tuning. These techniques help improve the accuracy and reliability of predictive models, making them more robust and effective in real-world applications.
Ensemble Methods: Random Forests and Gradient Boosting
Ensemble methods combine multiple individual models to create a stronger predictive model. Random forests and gradient boosting are two popular ensemble methods used in predictive modeling.
- Random forests: This method creates multiple decision trees during the training phase and outputs the average prediction of all the individual trees. It helps reduce overfitting and increases the accuracy of the model by combining the predictions of multiple trees.
- Gradient boosting: In this method, the predictive model is built in a stage-wise fashion, where each new model corrects errors made by the previous ones. Gradient boosting is effective in handling complex relationships in data and improving the predictive performance of the model.
Cross-Validation and Model Validation
Cross-validation is a crucial technique used to assess the performance of predictive models. It involves partitioning the data into multiple subsets, training the model on a subset, and testing it on the remaining subsets. This process helps evaluate the model’s generalization ability and identify potential issues like overfitting.
Cross-validation helps ensure that the predictive model is robust and reliable by testing it on different subsets of data.
Hyperparameter Tuning for Model Optimization
Hyperparameters are parameters that are set before the learning process begins. Hyperparameter tuning involves finding the optimal values for these parameters to improve the performance of the predictive model.
- Grid search: This technique involves defining a grid of hyperparameters and searching for the best combination of values through an exhaustive search. It helps identify the optimal hyperparameters for the model.
- Random search: Unlike grid search, random search selects hyperparameter values randomly from a specified range. This approach can be more efficient in finding good hyperparameter values, especially when the search space is large.
In conclusion, the realm of predictive modeling techniques offers a dynamic landscape of possibilities for harnessing data insights, driving innovation, and optimizing decision-making processes in an ever-evolving digital era. Dive deep into this transformative field and unlock a world of predictive analytics wonders.
When it comes to managing data, the debate between data lake and data warehouse continues. While data lakes store vast amounts of raw data in its native format, data warehouses organize structured data for easy analysis. On the other hand, enterprise data warehouses are designed to handle large volumes of data from various sources efficiently. To streamline data processing, businesses can utilize data aggregation tools that help consolidate and summarize information from multiple sources.
When it comes to managing and analyzing large volumes of data, the debate between data lake vs data warehouse continues to be a hot topic in the tech industry. While data warehouses are structured repositories for organized data, data lakes offer a more flexible and scalable approach for storing raw data. On the other hand, enterprise data warehouses cater to the specific needs of large organizations by providing a centralized repository for all their data.
To effectively handle data from various sources, businesses can leverage data aggregation tools that help consolidate and analyze information from different platforms.