
With Cloud-based data lakes at the forefront, organizations are embracing a new era of data management and insights. Dive into the world of scalable and flexible data solutions that are reshaping industries and decision-making processes.
Overview of Cloud-based Data Lakes
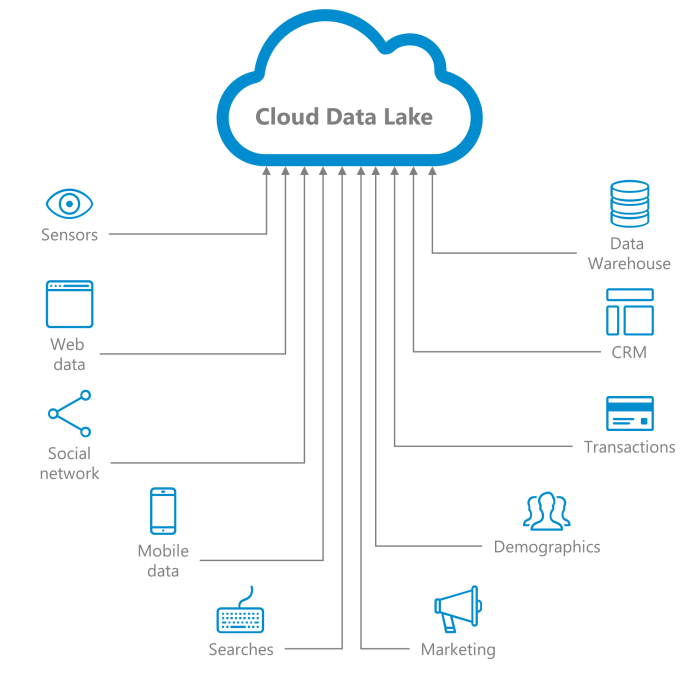
A cloud-based data lake is a centralized repository that allows organizations to store and analyze vast amounts of structured and unstructured data in its native format. Unlike traditional data storage solutions that require data to be structured before storage, a data lake can store raw data and apply schema on read when needed.
With the rise of cloud data warehousing , organizations can now store and manage vast amounts of data in a scalable and cost-effective manner. This technology offers greater flexibility and accessibility for data analytics and reporting.
Benefits of Cloud-based Data Lakes
- Scalability: Cloud-based data lakes can easily scale up or down based on the organization’s needs, allowing for seamless storage of massive amounts of data.
- Flexibility: These data lakes offer flexibility in terms of data types and sources, enabling businesses to ingest data from various platforms and formats.
- Cost-Effectiveness: By leveraging cloud infrastructure, organizations can reduce hardware and maintenance costs associated with traditional on-premise solutions.
Use Cases of Cloud-based Data Lakes
- Healthcare: Cloud-based data lakes are used in healthcare for storing and analyzing patient data, medical records, and research data to improve patient care and treatment outcomes.
- Retail: Retail companies utilize data lakes to analyze customer behavior, sales trends, and inventory management for better decision-making and personalized marketing strategies.
- Finance: In the finance industry, cloud-based data lakes help in fraud detection, risk management, and compliance by processing large volumes of financial data in real-time.
Scalability and Flexibility of Cloud-based Data Lakes
Cloud-based data lakes offer unparalleled scalability and flexibility compared to traditional on-premise solutions. Organizations can easily adjust storage capacity, processing power, and data analytics tools in the cloud environment, ensuring optimal performance and resource utilization.
When it comes to data source integration , businesses need to ensure seamless connectivity between various data points. This process involves combining data from different sources to provide a comprehensive view for analysis and decision-making.
Components of Cloud-based Data Lakes

The key components required to set up a cloud-based data lake are crucial for ensuring efficient data management and analysis in the cloud environment.
Role of Cloud Storage Services
- Cloud storage services like Amazon S3, Google Cloud Storage, or Azure Blob Storage play a vital role in building data lakes by providing scalable and durable storage solutions for storing large volumes of data.
- These services offer high availability, reliability, and security features that are essential for maintaining the integrity of data lakes.
- They also support various data formats and integration with other cloud services, making them ideal choices for building robust data lake architectures.
Data Ingestion, Processing, and Querying Tools
- Data ingestion tools are used to collect and transfer data from various sources into the data lake, ensuring that data is continuously updated and available for analysis.
- Data processing tools help cleanse, transform, and prepare the data for analysis, enabling organizations to derive meaningful insights from their data lakes.
- Querying tools allow users to interact with the data lake, run complex queries, and extract valuable information efficiently, facilitating data exploration and analysis.
Security Measures and Data Governance Practices
- Implementing robust security measures, such as encryption, access controls, and monitoring, is essential for protecting sensitive data stored in cloud-based data lakes from unauthorized access and potential threats.
- Data governance practices, including data classification, metadata management, and compliance monitoring, help ensure data quality, consistency, and regulatory compliance within the data lake environment.
- By establishing proper security and governance frameworks, organizations can maintain data integrity, privacy, and confidentiality in their cloud-based data lakes, fostering trust and reliability in their data-driven decision-making processes.
Architecture Design for Cloud-based Data Lakes

When designing a cloud-based data lake, it is crucial to consider the architecture to ensure optimal performance, scalability, and cost-effectiveness. The architecture design will impact how data is ingested, stored, processed, and accessed within the data lake environment.
Centralized vs. Decentralized Architecture Approach
- A centralized architecture approach involves storing all data in a single location within the cloud, making it easier to manage and govern. However, it may lead to bottlenecks and performance issues as the data lake grows in size.
- On the other hand, a decentralized architecture approach distributes data across multiple storage locations, allowing for greater scalability and flexibility. This approach can improve performance but may require more complex data management processes.
Data Partitioning, Indexing, and Data Lifecycle Management
- Data partitioning involves dividing data into smaller subsets based on specific criteria, such as date, region, or category. This helps optimize query performance and parallel processing within the data lake.
- Indexing is essential for quick data retrieval by creating indexes on key columns or attributes. This speeds up query processing and improves overall data lake performance.
- Data lifecycle management involves defining policies for data retention, archiving, and deletion. Proper lifecycle management ensures that only relevant data is stored in the data lake, reducing storage costs and improving efficiency.
Best Practices for Scalable and Cost-effective Architecture
- Utilize cloud-native services for data storage, processing, and analytics to take advantage of scalability and cost-efficiency offered by cloud providers.
- Implement data governance and security measures to ensure data integrity and compliance with regulations while designing the architecture.
- Use automation for data ingestion, transformation, and management processes to reduce manual effort and improve operational efficiency.
- Regularly monitor and optimize the architecture based on performance metrics and user feedback to continuously improve the data lake environment.
Challenges and Solutions in Cloud-based Data Lakes

Data lakes in the cloud offer numerous advantages, but they also come with their own set of challenges. Addressing these challenges is crucial to ensuring the success of cloud-based data lake implementations.
Data Integration Challenges and Solutions
Data integration is a common challenge in cloud-based data lakes, as data from various sources needs to be ingested and integrated seamlessly. One solution to this challenge is to use ETL (Extract, Transform, Load) processes to harmonize and consolidate data from multiple sources before loading it into the data lake.
- Implementing data pipelines with tools like Apache Spark or Apache Flink can help automate the data integration process.
- Utilizing data cataloging tools can provide a centralized repository for metadata management, making it easier to track and manage data across different sources.
Data Quality Challenges and Solutions
Maintaining data quality is essential in a cloud-based data lake environment to ensure accurate and reliable insights. One solution to this challenge is to establish data quality monitoring processes and implement data cleansing mechanisms.
- Implementing data validation rules and data profiling techniques can help identify and rectify data quality issues proactively.
- Leveraging data quality tools and platforms can automate data cleansing processes and ensure data consistency and accuracy.
Cost Management Challenges and Solutions, Cloud-based data lakes
Managing costs associated with cloud-based data lakes can be a significant challenge, especially as data volumes grow. One solution to this challenge is to optimize data storage and processing costs through efficient resource utilization.
- Implementing data lifecycle management strategies can help archive or delete data that is no longer needed, reducing storage costs.
- Leveraging serverless computing services can help scale resources dynamically based on workload demands, optimizing cost-efficiency.
Impact of Data Governance and Compliance
Data governance policies and compliance requirements play a critical role in managing data in a cloud-based data lake. Ensuring data security, privacy, and regulatory compliance is essential to building trust and maintaining data integrity.
- Establishing data governance frameworks and enforcing access controls can help protect sensitive data and ensure compliance with data regulations.
- Leveraging encryption and tokenization techniques can safeguard data both at rest and in transit, enhancing data security in the cloud environment.
Successful Implementations and Case Studies
Real-world examples of successful implementations of cloud-based data lakes showcase how organizations have overcome specific challenges to achieve valuable insights and operational efficiencies. Companies like Netflix, Airbnb, and Uber have leveraged cloud-based data lakes to analyze vast amounts of data and drive data-driven decision-making.
- Netflix utilizes AWS cloud services to manage petabytes of data and deliver personalized recommendations to users, showcasing the scalability and performance of cloud-based data lakes.
- Airbnb uses Google Cloud Platform to process diverse data types and gain actionable insights for improving user experiences and optimizing business operations.
- Uber leverages Microsoft Azure for real-time data processing and analytics, enabling dynamic pricing strategies and efficient resource allocation based on data insights from their cloud-based data lake.
In conclusion, Cloud-based data lakes offer a powerful platform for organizations to harness the potential of big data. With enhanced scalability, security, and efficiency, these innovative solutions pave the way for data-driven success in the digital age.
Choosing the right data collection methods is crucial for obtaining accurate and valuable insights. From surveys and interviews to web scraping and IoT devices, businesses have a wide range of techniques to gather data effectively.