
Data lake vs data warehouse sets the stage for this enthralling narrative, offering readers a glimpse into a story that is rich in detail with semrush author style and brimming with originality from the outset.
In the realm of data management, the distinction between a data lake and a data warehouse plays a crucial role in shaping how organizations handle and analyze their data. Let’s delve into the intricacies of these two concepts to understand their significance and functionality.
Data Lake Overview

Data lakes are centralized repositories that allow organizations to store a vast amount of structured and unstructured data at any scale. Unlike traditional data warehouses, data lakes store data in its raw form without the need for prior structuring or modeling.
Architecture of a Data Lake
Data lakes typically consist of three layers: the landing zone, the storage zone, and the processing zone. The landing zone is where raw data is initially ingested, while the storage zone stores the data in its original format. The processing zone is where data is transformed and prepared for analysis.
- The landing zone: This is the entry point for all data into the data lake. Raw data from various sources is ingested into this layer without any transformation.
- The storage zone: In this layer, data is stored in its original format, whether it’s structured, semi-structured, or unstructured. This allows for flexibility in data processing and analysis.
- The processing zone: Data in the storage zone is transformed and prepared for analysis in this layer. This is where data cleaning, structuring, and modeling take place before analysis.
Types of Data Stored in a Data Lake
Data lakes can store a variety of data types, including:
- Structured data: Traditional relational databases, such as customer information, transaction data, and financial records.
- Semi-structured data: Data that doesn’t fit neatly into a relational database structure, such as JSON or XML files.
- Unstructured data: Text documents, videos, images, social media posts, and other data types that don’t have a predefined format.
Data Warehouse Overview

A data warehouse is a central repository that stores structured data from various sources for reporting and data analysis. It is designed to support business decision-making processes by providing a consolidated view of historical data.
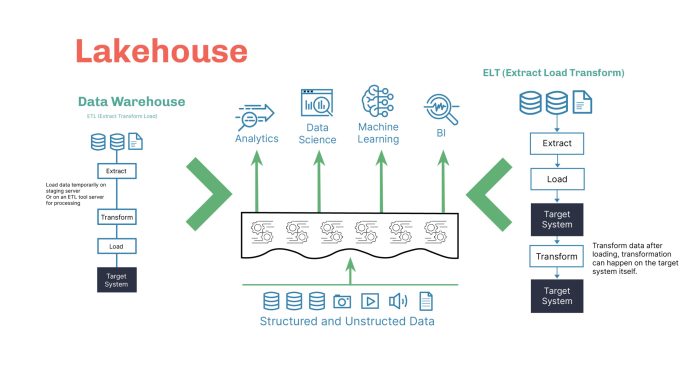
The architecture of a data warehouse typically consists of three layers:
1. Data Sources: This layer includes various data sources such as transactional databases, CRM systems, ERP systems, and other sources where data is generated.
2. Data Storage: The data storage layer is where the data is stored in a structured format optimized for querying and reporting. It often involves the use of relational databases or data warehouses like Oracle, SQL Server, or Snowflake.
3. Data Presentation: The data presentation layer is where users can access and analyze the data through reporting tools, dashboards, and visualization applications.
Types of data stored in a data warehouse include:
– Structured Data: Data that is organized into a predefined format, such as tables and columns, making it easy to query and analyze.
– Historical Data: Data that captures past events and transactions, allowing for trend analysis and forecasting.
– Aggregated Data: Summarized data that is preprocessed for faster query performance and reporting.
– Metadata: Information about the data stored in the warehouse, including data definitions, data lineage, and data quality metrics.
Data Warehouse Architecture, Data lake vs data warehouse
A data warehouse typically follows a three-tier architecture, consisting of data sources, data storage, and data presentation layers. Each layer plays a crucial role in the overall functionality of the data warehouse.
- Data Sources: This layer connects to various data sources and extracts data for storage in the warehouse.
- Data Storage: Data is stored in a structured format optimized for reporting and analysis, often using relational databases.
- Data Presentation: Users interact with the data through reporting tools and visualization applications to derive insights for decision-making.
By structuring data in a data warehouse, organizations can gain a comprehensive view of their business operations, enabling better decision-making and strategic planning.
Data Storage and Structure
Data lakes and data warehouses have distinct storage structures that cater to different data management needs. Let’s explore how data is stored and managed in each, as well as the key differences in data organization between the two.
Data Storage in Data Lakes
Data lakes store vast amounts of raw, unstructured data in its native format. This includes structured data from relational databases, semi-structured data like CSV files, and unstructured data like text files, images, and videos. Data lakes are designed to ingest data rapidly without the need for extensive preprocessing, allowing for flexibility in data storage.
- Data in data lakes is stored in a flat architecture, meaning there are no specific data models or schemas imposed on the data.
- Files are stored in their original form, preserving the data’s integrity and enabling various data processing and analytics tasks.
- Data lakes use distributed file systems like Apache Hadoop or cloud storage solutions to scale storage capacity according to data volume.
Data Storage in Data Warehouses
Data warehouses, on the other hand, are optimized for storing structured and processed data that is ready for analysis. Data is typically transformed, cleaned, and organized into a schema before being loaded into the warehouse for querying and reporting purposes.
- Data warehouses use a relational database management system (RDBMS) to store data in tables with predefined schemas.
- Data is structured into dimensions and fact tables, following a star or snowflake schema, to support complex queries and ensure data consistency.
- Data warehouses rely on indexing and partitioning techniques to optimize query performance and facilitate data retrieval.
Data Processing and Analysis: Data Lake Vs Data Warehouse

Data processing in a data lake involves storing raw data in its native format without the need for schema definition upfront. This allows for the collection of vast amounts of data from various sources, which can be structured or unstructured. The data is then processed and transformed as needed for analysis.
Data Processing in Data Lake
- Raw data is ingested into the data lake without any transformation.
- Data is stored in its native format, preserving its original structure.
- Data processing is done on-demand when needed for analysis.
- Schema-on-read approach is used, allowing flexibility in data exploration.
Analytics Capabilities
- Data lakes offer scalability and flexibility for storing and processing large volumes of data.
- Data warehouses are optimized for querying and analyzing structured data quickly.
- Data lakes support a wide range of analytics tools and techniques, including machine learning and AI.
- Data warehouses are ideal for complex SQL queries and business intelligence reporting.
Data Analysis and Utilization
- Data in a data lake is analyzed using tools like Apache Spark, Hadoop, and Presto for processing large datasets.
- Data lakes allow for exploratory data analysis and data discovery without predefined schemas.
- Data warehouses use SQL queries and OLAP techniques for structured data analysis.
- Data warehouses are optimized for fast query performance and are suitable for business intelligence reporting.
As we wrap up our exploration of data lakes and data warehouses, it becomes evident that each serves a unique purpose in the realm of data management. While data lakes offer flexibility and scalability for storing various types of data, data warehouses excel in providing structured data for analysis. Understanding the differences between these two systems is key to optimizing data utilization and decision-making in any organization.
Real-time data integration is crucial for businesses to make informed decisions quickly. By implementing real-time data integration , companies can access up-to-date information and respond promptly to changes in the market. This process ensures that data is continuously synced across various systems, enabling seamless operations.
ETL processes play a vital role in data management by extracting, transforming, and loading data from different sources into a centralized repository. With effective ETL processes in place, organizations can ensure data quality and consistency, facilitating accurate analysis and decision-making.
Choosing the right data integration tools is essential for streamlining the integration process and optimizing data workflows. These tools help businesses connect disparate data sources, automate data processing tasks, and enhance data governance practices, ultimately improving overall operational efficiency.